Eduardo José Gómez Hernández
This is blog is no longer a mirror. It is now the main location of the blog :)
by Topic
- TheZZAZZGlitch's April Fools Event
- Splash-4
- Random
by Date
2025
2023
- October
- May
- April
- February
I joined Qualcomm Ireland
Hey everyone, this has been a real rollercoaster. First of all, I defended my PhD on June 3rd :D
However, that was not all. On September, after several interviews with different companies, I decided at 3 am to join Qualcomm Ireland in the Post-Silicon PnP team.
I was not actively looking for a job yet. I had discussed with my advisor the opportunity to remain for one more year after the PhD, and we were already thinking about how to proceed in the following years. I got a master's student to continue what I was doing. I had started to prepare my teachings that year...
However, before that, in June/July, I decided to do some interviews to scout the market and learn how to do them (I had only done one before that point).
In very little time, two big companies started some interviews with me, and through a friend, I got in contact with another person looking for recent finishing researchers.
At this moment, already in September, I was starting to dislike University Procedures. Just because of a technicality, I had to delay my PhD submission from September to March. This forced me to remain as a PhD researcher, which, due to some limitations, I was earning much less money than in the previous years. I was not looking for money, but instead something I love doing.
While I was not looking for anything serious, one of them was giving an insine amount of money. Frustrated by the delays in my PhD process, I considered leaving academia to pursue a new path where I could continue learning about computers, my true passion.
After all the interviews, only 2 remain. At some point, I accepted the insane amount of money offered by one of them and rejected the other one (Qualcomm). However, they offered to do a call because the amount of money I requested (nearly double the offer) was impossible. After some conversations and last-minute talks, they improved the offer slightly.
The following days, I was fighting to decide what to do, and as I previously mentioned, I ended up deciding to go to Qualcomm. I rejected the offer I had accepted at the other company, and just one week later, I was on a plane to Ireland.
My new adventure started 2 days after, on Sunday, when, without being sure until Monday, I met my American boss on the street while walking alongside the office.
That is all for now. Just for context, my first day at the Qualcomm office was October 7, 2025. I will never forget that day, a lot of things happened.
Best Regards, OdnetninI
SPLASH-4 Article #5: A special version Release - Splash-4.0.1
After so long, a new article is out :)
During the development of another different project, a question arose about the last Lock that remains in Volrend. So, we decided to tackle it, and if necessary, build another version if the results are relevant enough.
The critical section is the following one:
LOCK(Global->CountLock);
printf("%3ld\t%3ld\t%6ld\t%6ld\t%6ld\t%6ld\t%8ld\n",my_node,frame,exectime,
exectime1,num_rays_traced,num_traced_rays_hit_volume,
num_samples_trilirped);
UNLOCK(Global->CountLock);
This section is used to print the progress of the application. Its output can be used to determine if the application ran successfully, however, because the order was random, the output was never used for this purpose and instead, the output tiff was used.
The new version moves this data to a shared structure and it is later print by thread 0, without the need for an extra synchronization (there was already a barrier after the code mentioned above.
Global->progress[my_node].frame = frame;
Global->progress[my_node].exectime = exectime;
Global->progress[my_node].exectime1 = exectime1;
Global->progress[my_node].num_rays_traced = num_rays_traced;
Global->progress[my_node].num_traced_rays_hit_volume = num_traced_rays_hit_volume;
Global->progress[my_node].num_samples_trilirped = num_samples_trilirped;
This new version is named "Volrend No Print Lock".
With this last change, we announce the new version Splash-4.0.1:
25 - October -2023: Release Splash-4.0.1
- NEW: A new version for Volrend, Volrend-no_print_lock. The progress printing lock at adaptative.c.in have been replaced with a memory location. After the barrier sync, thread 0 prints all the progress in order.
Besides the reduction in unnecessary synchronization, the output is always in thread+frame order.
- FIX: The CLOCK macro has been replaced with a high-res, more info at issue #2
- MINI: SPLASH3_ROI_BEGINand SPLASH3_ROI_END have been replaced with SPLASH4_ROI_BEGIN and SPLASH4_ROI_END
Remember, the new version is available at the repository: https://github.com/OdnetninI/Splash-4
Best Regards, OdnetninI
Finally!!! I have implemented something very close to a compiler
I am still preparing two posts for explaning why I did this, but as they are not yet ready, let me give you a very small summary:
Every year, the Youtuber "TheZZAZZGlitch" (a.k.a. zzazz) creates a challenge named "TheZZAZZGlitch's April Fools Event". Typicaly this event is run Gameboy or Gameboy Advance with some unmodified Pokemon ROM and a custom Save file. There is an exploration part, where everyone without technical knowledge can play and solved without any issue. But, there is also a secondary part which includes the understanding of several topics: Reverse Engineering, Networking, Assembly (LR35902, ARM), Quick prototyping, among many others. I've been participating since 2017 each year, most of them teamed with by friend Radixan.
However, this year was special, zzazz did not have enough time to prepare a full challenge, they got a new job in Microsoft and they are preparing cybersecurity conferences, so they did an more Capture The Flag challenge (CTF). This time, there was an invented 16-architecture that has its own instructions, applications, environment...
Okay, but how a compiler is related with a CTF challenge?
Well, after the challenge finished, we were waiting for zzazz to release the source code of the challenge, like they usually do. But there was no luck, only the leaderboard got released.
So, I did my own. I have implemented 99% of the challenge. I will not enter in details, as I am detailing everything in another post, but in summary, there are some information missing that we were not able to recover before the challenge server died. However, it is possible to emulate enought of it to make the Flag available.
The point was, that, during the development of the replica of the challenge, I wanted to have some tools to Assemble and Disassemble the binaries of the challenge.
The Disassembler was easy, we already done it during the challenge itself, it required some tinkering and refactorization, but it worked. The main issue was the Assember. I didn't want just a simple assembler that process line by line, I wanted to have labels, constants, string reallocation, expressions... Just some things that make life easier for developers.
As the challenge did not have an specific assembly language, I invented my own, based on x86, ARM, Z80, 6202, ... everything I already know.
I splited the challenge of making the assembler in two steps:
- Make an small dirtier version that just works, even if instructions need to change to make my life easier (like "
movi" instead of the generic "mov" to indicate that we are using a number instead of a register).
- When it works, refine the assembly language and create an assembler that has at least 4 modules: Lex, Grammar, Code, Symbols.
The first version, was a nightmare, a lot of small tricks, and hardcoded things to make it work. But it did :) This assembler:
The second version, was a bit better (https://github.com/OdnetninI/zzazz-2023-server/tree/main/tools/assember), however, some things are still done for quicker development. For example, the code does not differentiate between "call" and "caZZ", it just assume that if it starts with letter 'c' then an 'a' follows it, and it is 4 characters long, it is "call".
But, after finishing some parts, adding more stuff, refining things, creating the symbol tables, allocating space, resolving symbols, doing the grammar maching... it end up being a compiler, a very simple one.
It is full of bugs, things that can be improved, better decissions could be done, but in the end, it works. I have tried so many times to implement a compiler, even during the Bachelor's I had a subject about it, but this is the first time I was able to implement something that works, done completely by myself and I am proud of it.
For some of you, this could be nothing, but for me, it was huge.
Please, check the code, and feel free to submit your improvements. The only requirement is that the already existing ".asm" files generate binary identical files to the challenge ones. I have some improvements in mind, but I need motivation to implement them.
This is all for this time.
Best Regards, OdnetninI
SPLASH-4 Article #4: Old-style data types
Welcome to the next Splash-4.1 article.
Sorry for not writing in a while, but I am preparing a lot of things, so I did not have too much free time.
Before the standardization of C built-in types in C99, it was very common to have large sections declaring types from the built-in ones:
// Extracted from raytrace
typedef char CHAR;
typedef char S8;
typedef unsigned char UCHAR;
typedef unsigned char U8;
typedef short SHORT;
typedef short S16;
typedef unsigned short USHORT;
typedef unsigned short U16;
typedef long INT;
typedef unsigned long UINT;
typedef unsigned long BOOL;
typedef long LONG;
typedef long S32;
typedef unsigned long ULONG;
typedef unsigned long U32;
typedef float FLOAT;
typedef float R32;
typedef double DOUBLE;
typedef double R64;
typedef double REAL;
In these cases, we have several possible solutions. The first one is to fix those typedefs with the right data type, which is the easiest solution. However, even being more time-consuming, it is better to use the correct data types in the code and remove the typedefs completely.
It is easy to think, that just a replacement in the full code with solve the issue. This is far from the truth.
Now, it is important to check all the uses of those types and replace some of them with better alternatives. For example, some variables can only be positive, so no need for them to be signed. Other variables can use fewer bits. There is a full set of changes that can be applied to optimize not only memory usage but also CPU usage.
Let me include an honorable mention, "bool". In the past, the boolean type was not implemented in the standard, so most people used unsigned/signed 8-bit variables to implement them, which helped with macros. Sometimes, longer types, and other types even without macros. But nowadays, the "stdbool" header solves this issue. However, even today, there are reasons why some programmers prefer avoiding the "bool" type, but this is a story for another time.
Nowadays, typedef is used for reducing the size of data type names (from "struct MyType" to "MyType"), giving more meaningful names (from "unsigned int" to "Index" or "index_t"), and when the data is meant to be changed by the user (from "float" to "Element_Type").
In the end, to conclude, this is a programmer's decision. But reasons to use typedefs have changed due to standardization, language evolution, and also other languages and programmers' influence. Everything evolves.
Best Regards, OdnetninI
SPLASH-4 Article #3: CLOCK is not enough to measure time
Hello again, folks 👋,
I got another request in my email asking if I had any clue why the benchmarks were reporting "0" or "nan" execution times.
I also noticed it, but never care about it as all my measures were done using the ROI with my custom code.
But, if I want to enable more people to use the Splash-4 benchmarks as a replacement for Splash-2, Splash-2X, or Splash-3, I have to fix these issues. Note that in Splash-4.1, these statistics will not exist as the synchronization point is slower than the code itself. I am still thinking of a way of solving this question.
Going back to the issue mentioned in the email. Why is the timer reporting "0" or "nan"?
Well "nan" could appear when there is a by zero division. So let's check if this is the case.
CLOCK(initdone);
...
CLOCK(finish);
...
Global->totaltimes[MyNum] = finish-initdone;
...
((double)Global->transtimes[0])/Global->totaltimes[0]
So, let's check how the CLOCK macro works
m4_define(CLOCK, `{long time(); ($1) = time(0);}')
The "time()" C call, as mentioned in the man 2 page:
time() returns the time as the number of seconds since the Epoch, 1970-01-01 00:00:00 +0000 (UTC).
So, the problem is easy to understand, the measured parts take less than 1 second to execute. And when the measure is done just at the border of two seconds, instead of "nan", the benchmarks spill out "0".
The main problem in solving this is that the variables, for measuring time, are 32 bits in most of the benchmarks. Therefore, in the future, this will be again an issue, but meanwhile, I find a better solution, I replaced the CLOCK macro with this one, that has a high-res timer.
m4_define(CLOCK, `{
struct timeval FullTime;
gettimeofday(&FullTime, NULL);
($1) = (unsigned long)(FullTime.tv_usec + FullTime.tv_sec * 1000000);
}')
I cannot point out the exact moment, but in Splash-2 I found both versions of the CLOCK macro, depending on the specific repository I look at. Also, in Splash-3 the problematic CLOCK macro is used.
After some testing, I declare the issue solved, for now.
Best Regards, OdnetninI
SPLASH-4 Article #2: FFT extra barriers and prefetch
Hello everyone 👋
Since I started developing Splash-4, I noticed that, more commonly the kernel apps, there are several synchronization points that are not needed at all.
After receiving an email asking about why some of the barriers were there, as they seem to be doing nothing, I started looking into them again.
One of the first things I noticed is that nearly half of the barriers in FFT were there just to be able to measure the time between different execution parts. However, in nowadays hardware and designs, these benchmarks execute extremely fast, this synchronization overhead is no longer insignificant.
BARRIER(Global->start, P);
if ((MyNum == 0) || (dostats)) {
CLOCK(clocktime1);
printf("Step 2: %8lu\n", clocktime1-clocktime2);
}
Therefore, after a deep analysis of which parts use data from other cores and when it is using its data, only three Barriers are required (four if reverse FFT is enabled to check the results). That is a great reduction from the original seven mandatory barriers.
Apart from the barriers, before starting computing, each thread tries to prefetch its data using:
TouchArray(x, trans, umain2, upriv, MyFirst, MyLast);
After doing some experiments on three different machines, I noticed that this "prefetch" was slowing down the application a little bit in some cases.
Prefetching could be important in specific architectures, which is why I decided to make it optional using the -y argument when executing the application.
I know this time there are no fancy graphs, but I hope to see you next time ☺
Best Regards, OdnetninI
SPLASH-4 Article #1: Introduction - Road to Splash-4.1
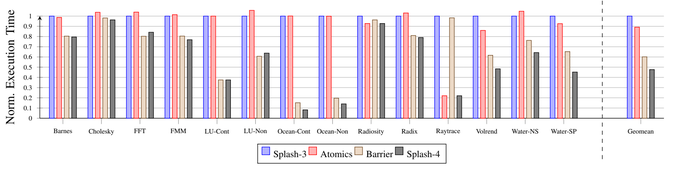
Hello everyone 👋
Several months ago, my research group and I released The Splash-4 Benchmark Suite. Published in IISWC2022 "10.1109/IISWC55918.2022.00015" and available in GitHub https://github.com/OdnetninI/Splash-4
This release was a big update on those very old benchmarks (over 25 years old), significantly reducing the synchronization overhead of running the benchmarks, reducing the execution time and increasing the performance of the applications.
However, even after 3 updates, no one has invested enough time into the applications to modernize the code to today's standards.
To begin, because most of the benchmarks were written in the early 90s, they follow very old C programming style. As an example, all the variables of a function are defined at the beginning. Creating a lot of lines that are not relevant at that moment when trying to understand the code.
During the development of the Splash (or probably Splash-2), the authors introduced the M4 macro system. M4 has several good features, it is much more evolved than the C preprocessor, but it has some several drawbacks. When using an external macro system, matching compiler errors with original source files is not trivial, this is the reason why the C preprocessor introduces several "#line" sentences after the preprocessor executes. Another drawback is that M4 uses positional arguments for the macros, and never checks the number of parameters.
Therefore, the main goal of Splash-4.1 is to modernize the source code to make them easier to read, removing external dependencies (like the M4 macro processor) and fix several bugs, remove synchronization overheads that are not needed. All these changes will allow future researchers to understand and modify the benchmarks as they need, without the hassle of reading near 30 years old code.
In the following articles, I plan to show some of the steps done, and the reason behind them.
So, I hope to see you around in the following post ☺
Best Regards, OdnetninI
Welcome!!
Hi everyone 😃,
I am OdnetninI (aka. Odi, Odnet or Eduardo) a Ph.D. Student at the University of Murcia. I plan to post several series of articles focused on different topics I encounter in my research career (sometimes also my life). Hope to see you soon 👋
Best Regards, OdnetninI